


이 기술은 디퓨전 모델을 기반으로 하여 기존 비디오 생성 모델의 한계를 극복한 것으로 평가받고 있다.
|

FIFO-Diffusion, 무한한 길이의 비디오 생성
기존의 비디오 생성 모델들은 영상의 길이가 길어질수록 메모리 소모가 급격히 증가하고, 프레임 간 일관성 유지가 어려워 부자연스러운 영상을 생성하는 한계가 있었다.
그러나 FIFO-Diffusion은 이러한 한계를 극복하며, 메모리 사용량을 일정하게 유지하면서도 각 프레임이 자연스럽게 이어지는 고화질 비디오를 생성할 수 있다.
이 기술은 사전에 짧은 클립을 통해 훈련된 디퓨전 모델이 추가 학습 없이 텍스트 조건에 맞춰 무한한 길이의 비디오를 생성하도록 설계됐다.
|
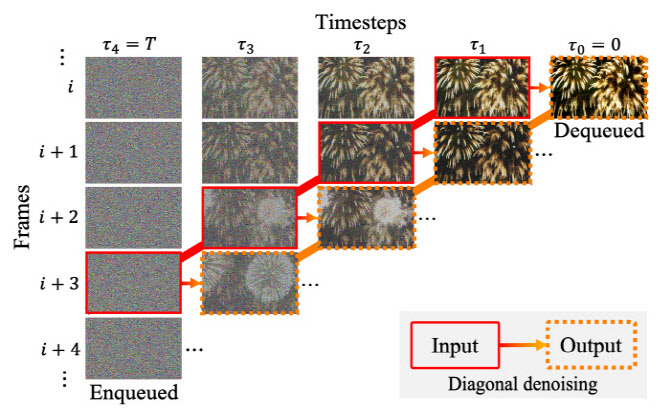
이번 연구에서는 비디오 생성 품질을 획기적으로 개선하기 위한 세 가지 혁신적 기법이 적용됐다.
첫째, 대각선 디노이징(diagonal denoising) 기법을 통해, 각기 다른 노이즈 레벨의 비디오 프레임을 동시에 처리하면서 품질 저하 없이 비디오를 생성할 수 있었다.
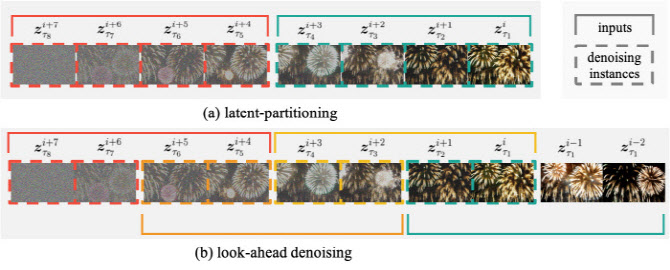
둘째, 잠재 파티셔닝(latent partitioning) 기법으로 프레임을 여러 블록으로 나누어 병렬 처리하며, 프레임 간 노이즈 레벨 차이를 줄였다.
셋째, 앞서보기 디노이징(lookahead denoising) 기법을 통해 새로 생성될 프레임이 이전에 생성된 깨끗한 프레임을 참조하도록 하여 후반부 프레임의 품질을 더욱 선명하게 유지했다.
|
FIFO-Diffusion 기술은 영화, 광고, 게임, 교육 등 다양한 콘텐츠 산업에 큰 영향을 미칠 것으로 기대된다. 기존의 텍스트 기반 비디오 생성 모델들은 3초 이내의 짧은 클립만을 생성할 수 있어 실제 콘텐츠 제작에는 제한적이었다. 그러나 FIFO-Diffusion은 길이 제한 없이 자연스러운 비디오를 생성할 수 있어 상용화되면 콘텐츠 제작 분야에 큰 변화를 가져올 전망이다. 또한, 대규모 하드웨어 자원이나 방대한 데이터가 필요하지 않기 때문에, AI 기반 영상 콘텐츠 제작의 활성화를 이끌 것으로 보인다.
NeurIPS 2024 발표 논문 채택
이번 연구 결과는 인공지능 및 기계학습 분야의 권위 있는 학술대회 NeurIPS 2024에서 발표 논문으로 채택되었다. NeurIPS는 AI 및 딥러닝 분야의 최신 연구 성과를 발표하는 세계적인 행사로, 이번 발표 논문은 엄격한 심사를 통과한 우수한 연구로 평가받고 있다.
연구를 이끈 한보형 교수는 “FIFO-Diffusion은 기존 비디오 생성 모델의 한계를 넘어서, 무한 길이의 비디오 생성이라는 새로운 개념을 수립한 기술로, 영상 콘텐츠 분야의 발전에 중요한 기여를 할 것”이라고 말했다. 또한, 논문의 주 저자인 김지환 연구원은 “이번 개발로 비디오 생성 기술이 영상 콘텐츠 산업에서 폭넓게 활용될 수 있는 토대가 마련됐다”고 강조했다.
김지환과 강준오 연구원은 현재 서울대 컴퓨터비전 연구실에서 비디오 생성 기술에 대한 후속 연구를 진행 중이다.






![[포토]벼랑 끝에 있는 최윤범 고려아연 회장](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111301728t.jpg)
![[포토]유상임 과기정토부 장관, 통신사 CEO 간담회](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111301573t.jpg)
![[포토]수능 D-1, 힘내라 고3!](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111301501t.jpg)
![[포토]서울시·의료계, '의료용 마약류 안전사용' 협약식](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111301459t.jpg)
![[포토]'악수하는 주호영-추경호'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111301245t.jpg)
![[포토]태광그룹 노동조합협의회, '김기유 구속하라'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111301220t.jpg)
![[포토]'모두발언하는 이재명 대표'](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111301017t.jpg)
![[포토]로제, 전세계 '아파트' 열풍으로 물들이고 입국](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111201326t.jpg)
![[포토]간호법 제정 축하 기념대회](https://image.edaily.co.kr/images/Photo/files/NP/S/2024/11/PS24111200857t.jpg)

![[포토]'이보미 골프 갤러리'오픈](https://spnimage.edaily.co.kr/images/vision/files/NP/S/2024/11/PS24111100375h.jpg)

![[단독]의대 휴학 승인 본격화했지만…1학년은 '유급'같은 휴학](https://image.edaily.co.kr/images/vision/files/NP/S/2024/11/PS24111301632h.jpg)
